

جلد 21، شماره 2 - ( تابستان 1403 )
جلد 21 شماره 2 صفحات 159-151 |
برگشت به فهرست نسخه ها

![]()
![]()
![]()
Download citation:
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:



BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
Esmaielpour A, Ameli M, Mozdgir A, Ahmadi O, Zarabi M. Predicting pre-collection umbilical cord blood clotting using advanced machine learning algorithms. bloodj 2024; 21 (2) :151-159
URL: http://bloodjournal.ir/article-1-1520-fa.html
URL: http://bloodjournal.ir/article-1-1520-fa.html
اسمعیل پور امیر حسین، عاملی مریم، مزدگیر اشکان، احمدی ارد، ضرابی مرتضی. پیشبینی لخته شدن خون بند ناف پیش از جمعآوری با کمک الگوریتمهای یادگیری ماشین پیشرفته. فصلنامه پژوهشی خون. 1403; 21 (2) :151-159



استادیار گروه مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی
متن کامل [PDF 535 kb]
(504 دریافت)
| چکیده (HTML) (2210 مشاهده)
مقدمه
خون بند ناف (Umbilical Cord Blood: UCB) منبع غنی از سلولهای بنیادی خونساز است که میتواند در درمان اختلالات ژنتیکی، نقص ایمنی و اختلالات خونی مورد استفاده قرار گیرد. پیوند خون بند ناف یک روش پزشکی است که در آن سلولهای بنیادی خون بند ناف یک نوزاد سالم به بیمار پیوند زده میشود. این پیوند برای درمان بیماریهای مختلفی از جمله سرطانهای خون، اختلالات خونی، سندرمهای نارسایی مغز استخوان و اختلالات ایمنی کاربرد دارد (1).
یکی از چالشهای اصلی در جمعآوری خون بند ناف، بروز لختههای خون در بند ناف است که مانع از جریان خون و کاهش تولید سلولهای بنیادی میشود. بدین ترتیب جمعآوری و ذخیرهسازی UCB با وجود لخته در بند ناف میتواند پیچیده شده و عملکرد سلولهای بنیادی را کاهش داده و کیفیت آنها را به خطر بیندازد؛ بنابراین، پیشبینی احتمال لختهشدن بند ناف قبل از جمعآوری میتواند به اطمینان از عملکرد بالاتر سلولهای بنیادی و نتایج بهتر برای بیماران کمک کند و به پزشکان در تصمیمگیری آگاهانه کمک نماید (2).
بند ناف از دو شریان و یک ورید تشکیل شده است که اکسیژن و مواد مغذی را به جنین میرساند و مواد زائد را دفع میکند. بند ناف همچنین حاوی ماده ژلاتینی به نام ژله وارتون است که از فشرده شدن رگها جلوگیری میکند. با این حال، در حین زایمان، بند ناف میتواند فشرده یا پیچ خورده شود و منجر به تشکیل لخته گردد. عوامل متعدد دیگری نیز ممکن است در شکلگیری لخته در خون بند ناف نقشآفرین باشند (3). برخی از این عوامل که ریشه در بیماریهای مادر و نوزاد دارند، مانند دیابت مادر در زمان بارداری، رابطه مستقیم با لختهشدن خون نوزاد دارند (4). حیفض و همکاران در پژوهش خود 52 مورد لخته شدن بند ناف از 3 جمعیت مختلف را مورد تجزیه وتحلیل قرار داده و با 68 مورد از ادبیات موضوع مقایسه کرد که بدین ترتیب مجموعهای از عوامل و بیماریهای مختلف را در شکلگیری لخته مورد بررسی قرار داد و به این نتیجه رسیـد کـه در نوزادان پسر احتمال بیشتری برای
لختهشـدن وجـود دارد (5). در این پژوهش عواملی همچون عوارض مامایی مانند انواع عفونت و شرایط سیستمیک جنین مانند دیابت و خونریزی جنینی مهم ارزیابی شدند. از جمله عامل دیگری که در ایجاد لخته تاثیرگذار است، کمخونی مادر میباشد (6). تغییرات انعقاد خون بند ناف در فشار خون مادر در پژوهش لاکس مورد بررسی قرار گرفت (7). این پژوهش همچنین به این نتیجه رسید که آسیب کبدی به عنوان یکی از اصلیترین علل انعقاد خون بند ناف نوزاد مطرح است.
با توجه به این که پیشبینی لخته شدن خون بند ناف پیش از زایمان میتواند منجر به بهبود کمیت و کیفیت شود و به علاوه صرفه جویی اقتصادی به همراه داشته باشد، لذا استفاده از مدلهای پیشبینی کننده در این زمینه، امری ضروری است. امروزه روشهای یادگیری ماشین (Machine Learning: ML) به عنوان ابزاری قدرتمند برای پیشبینی پدیدهها و متغیرهای مختلف در علوم گوناگون به کار میروند. هر چند هنوز مطالعهای به منظور پیشبینی لختهشدن خون بند ناف با این ابزار صورت نگرفته است. از این رو در ادامه پژوهشهایی که از ML برای کنترل کیفیت سلولهای بنیادی استفاده کردهاند، مورد بررسی قرار میگیرند.
هدف بسیاری از پژوهشها در این حوزه تعریف پیشبینیکنندههای بالینی قبل از تولد برای تعداد سلولهای هستهدار (Total Nucleated Cell count: TNC) است که به شناسایی اهداکنندگان موفق واحدهای خون بند ناف قبل از شروع زایمان فعال کمک میکند. این پژوهشها با پیشبینی TNC تلاش میکنند تا کارآیی بانک خون در ذخیرهسازی نمونههای بهتر را افزایش دهند. این مطالعهها از روشهای یادگیری گروهی (Ensemble Learning) و روشهای کلاسیک ML مانند درخت تصمیم استفاده کردند (9، 8). همچنین هاره با کمک رگرسیون به این نتیجه رسید که سن حاملگی، نژاد مادر و وزن و جنس نوزاد با TNC ارتباط دارد (11، 10). با کمک یادگیری ماشین و روشهای آماری مختلف مانند شبکههای عصبی پرسپترون چند لایه، رگرسیون لجستیک و درخت تصمیم، ارزش کیفـی نمونههـای خـون و دستهبنـدی مناسب آنها
(برای دور انداختن یا انجماد) را تعیین کرد.
همان طور که پژوهشهای بالا نشان میدهند، روشهای یادگیری ماشین توانایی لازم برای ارائه پیشبینی کیفیت خون بند ناف را دارا هستند اما این روشها برای پیشبینی وجود و یا بروز لخته در خون بند ناف پیش از زایمان استفاده نشدهاند. هدف این مقاله، پیشبینی لختهشدن خون بند ناف پیش از جمعآوری نمونهها از اهداکنندگان با کمک روشهای یادگیری ماشین پیشرفته بود. عملکرد الگوریتمهای مختلف یادگیری ماشینی برای پیشبینی لختهشدن خون بند ناف ارزیابی شده و در مورد پیامدهای بالقوه این یافتهها برای عمل بالینی بحث میشود.
مواد و روشها
در این پژوهش از زبان برنامهنویسی پایتون (Python) استفاده شده است که یک زبان برنامهنویسی سطح بالا و همه منظوره است. پایتون یک زبان قدرتمند با طیف گستردهای از کتابخانهها و ابزارها محسوب میشود. تا سال 2020، 89% پژوهشهای مربوط به ML با کمک زبان پایتون نوشته شده است (12).
توصیف مجموعه دادهها:
این پژوهش از نوع گذشتهنگر بود. دادهها شامل
928127 نمونه جمعآوری شده در بانک خون بند ناف رویان از سال 1384 تا 1400 بود. این دادهها ۸۶ ستون (ویژگی) شامل اطلاعات مربوط به لخته شدن و برخی از ویژگیهای هر اهداکننده هستند. معیار انتخاب این ویژگیها در دسترسبودن و قابلیت اندازهگیری آنها پیش از تولد نوزاد بود. ویژگیهایی که تعداد رکوردهای آنها به طور قابلتوجهی از دست رفته بود نیز حذف شدند. در نهایت تعداد ستونهای مورد بررسی (بدون ستون هدف یعنی لخته بودن خون بند ناف) ۳۲ ویژگی را تشکیل دادند. لازم به ذکر است که ویژگیهای مربوط به سابقه بیماری در خانواده، پیش از این و توسط مجموعه بانک خون رویان به کمک پرسشنامهای آنلاین جمعآوری شده است. برای دادهها و رکوردهایی که ازدست رفته و یا پرت بودند، سطر مربوط به آنها از بین مجموع سطرها حذف شد. در یادگیری ماشین، الگوریتمها بر اساس ویژگیهایی که از دادهها استخراج میشوند، یاد میگیرند. این ویژگیها در واقع پیشبینی کنندههای لختگی خون بند ناف هستند یعنی نشانههایی هستند که به الگوریتم کمک میکنند تا الگوهایی را در دادهها شناسایی کند و از آنها برای پیشبینی یا تصمیمگیری استفاده کند (13). در شکل گامهای پژوهش به منظور پیشبینی بروز لخته به صورت شماتیک رسم شدهاند (شکل 1).

ستون هدف برای پیشبینی لخته بودن خون بند ناف پیش از اهدا شامل دو دسته به صورت باینری است. دسته اول شامل نمونههایی است که دارای لخته هستند و دسته دوم شامل نمونههایی است که لخته ندارند.
با توجه با این که دسته اول شامل 25089 نمونه و دسته دوم شامل 100765 نمونه بود، مشخص میشود دادهها نامتوازن هستند. در الگوریتمهای طبقهبندی استاندارد، توزیع کلاسها متوازن در نظر گرفته میشود و این دسته از الگوریتمها در مواجهه با مجموعهدادههای نامتوازن، عملکرد مناسبی را از خود ارائه نمیدهند؛ چرا که الگوریتمهای معمول طبقهبندی به سمت نمونههای آموزشی کلاس بزرگتر متمایل میشوند که این موضوع باعث افزایش خطا در شناسایی نمونههای اقلیت میشود (14). به منظور مقابله با این مشکل، در این پژوهش از روش نمونهبرداری بیش از حد اقلیت مصنوعی (Synthetic Minority Oversampling Technique: SMOTE) استفاده شد که امکان تولید دادههای مصنوعی را فراهم میسازد. این روش با استفاده از همسایههای هر نمونه از کلاس اقلیت، نمونههای مصنوعی جدیدی میسازد. به این صورت که در مرحله اول، بهازای هر نمونه
جدید در نظر گرفته میشوند.
برای انتخاب بهترین ویژگیها برای استفاده در الگوریتمهای یادگیری ماشین و بهبود کیفیت آنها از روش طبقهبندی درختان مازاد (Extra Tree) استفاده شد. الگوریتم درختان مازاد، مانند الگوریتم جنگلهای تصادفی، درختهای تصمیمگیری زیادی ایجاد میکند، اما نمونهگیری برای هر درخت، تصادفی و بدون جایگزینی است (15).
روشهای یادگیری ماشین:
برای اجرای مدل اصلی با به کارگیری تعدادی از الگوریتمهای یادگیری ماشین با ناظر و اجرای آن بر روی دادههایی که در بخش قبلی بررسی شدند، بروز لخته در خون بند ناف نوزاد پیش از تولد پیشبینی شد.
به منظور ارزیابی دقت و کارآیی الگوریتمها در پیشبینی، از جمله شاخصهایی که مورد بررسی قرار گرفتهاند شامل دقت (Accuracy) صحت (Precision)، بازخوانی (Recall) و امتیاز

برای تنظیم فراپارامتر (Hyperparameter) در الگوریتمهای یادگیری ماشینی از روش جستجوی شبکهای (Grid Search) استفاده شد که شامل جستجو در محدودهای از مقادیر فراپارامتر برای یافتن ترکیب بهینه فراپارامترها است که بهترین عملکرد را در یک مجموعه داده معین ایجاد میکند (16). فراپارامترهای کلیدی و اندازههای آزمایش بر اساس تأثیر قابل توجه آنها بر عملکرد و کارآیی محاسباتی مدل انتخاب شدند، که امکان ایجاد فضای جستجوی قابل مدیریت را فراهم میآورد و در عین حال نتایج بهینهسازی قوی را تضمین میکند. همچنین لازم به ذکر است که پس از فراخوانی دادهها و اجرای روش SMOTE ، آنها به دو دسته دادههای تمرینی (80%) و دادههای تست (20%) تقسیم شدند.
الگوریتمهای مورداستفاده در این پژوهش شامل الگوریتمهای زیر است:
یافتهها
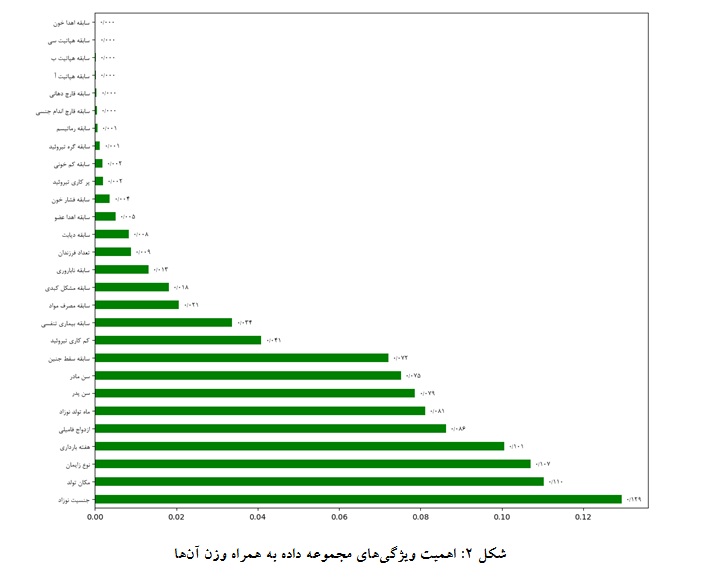
پس از متوازنسازی دادهها با روش SMOTE مجموعه دادهها برای انتخاب بهترین ویژگیها آماده شدند. پس از اجرای الگوریتم درختان مازاد میتوان دید که ویژگی "جنسیت نوزاد" با مقدار وزن 12/0 بیشترین تأثیر را در مدل دارد. پس از آن، ویژگیهای "مکان تولد" و "نوع زایمان" به ترتیب با وزنهای 11/0 و 10/0 قرار دارند. ویژگیهای دیگری مانند "هفته بارداری" و "ازدواج فامیلی" نیز تأثیر قابل توجهی دارند. در مقابل، ویژگیهایی مانند "سابقه اهدا خون" و "سابقه هپاتیت C " کمترین اهمیت را در مدل دارند( شکل 2). شکل 2 نمایی از اهمیت تمام ویژگیها را نشان میدهد که محور افقی میزان اهمیت هر ویژگی و محور عمودی نام ویژگیها را نشان میدهد. ویژگیها بر اساس اهمیت و وزن داده شده توسط الگوریتم به صورت نزولی مرتب شدهاند. بر این اساس ۱۸ ویژگی با بیشترین اهمیت (جنسیت نوزاد تا سابقه فشارخون) برای اجرای الگوریتمهای بعدی انتخاب میشوند.
نتایج نشان میدهد که جنگل تصادفی بهترین دقت (84/0)، بالاترین صحت (95/0) و امتیاز F1 (84/0) را به اجرا گذاشته است اما بازخوانی متوسط (73/0) میتواند نشاندهنده این باشد که این مدل در شناسایی همه موارد مثبت موثر نیست. مدل k-نزدیکترین همسایه با دقت (83/0)، صحت (80/0)، بازخوانی (89/0) و امتیاز F1 (84/0) کارآیی بالایی در همه شاخصها را از خود نشان داده است و بیانگر آن است که برای پیشبینی لختهشدن خون بند ناف مناسب اسـت. رأیگیـری اکثریت و درخت تصمیم عملکرد نسبتاً خوبی را در همه شاخصها از خود نشان داده است و مشخص میکند که میتوان از آنها نیــز
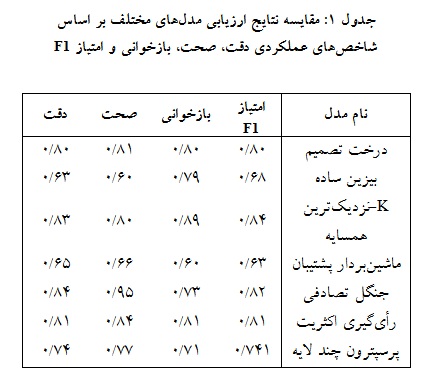
به عنوان الگوریتمهای قابل اطمینان برای پیشبینی لخته استفاده کرد. پرسپترون چندلایه نتایج نسبتاً متوسطی را در مقایسه با دیگر روشها نتیجه داده است. دستهبندی بیز ساده با وجود بازخوانی نسبتا خوب (79/0) عملکرد ضعیفی در دیگر شاخصها دارد. ماشین بردار پشتیبان اما عملکرد ضعیفی نسبت به سایر مدلها دارد که میتوان گفت استفاده از این روش برای پیشبینی لخته مناسب نیست. بعد از اجرای هر الگوریتم و عیبیابی، کارآیی الگوریتمها با هم مقایسه شدند (جدول 1).
بحث
در این مطالعه مدل یادگیری ماشینی برای پیشبینی لختهشدن خون بند ناف پیش از تولد نوزاد با استفاده از دادههای بالینی و آزمایشگاهی طبقهبندی شد. شناسایی بند نافهایی که در معرض خطر بروز لختهشدن هستند، تأثیر به سزایی در کیفیت خون جمعآوری شده به منظور ذخیرهسازی در بانکهای بند ناف و همچنین کاهش هزینه جمعآوری و آزمایش در این بانکها دارد. استفاده از یادگیری ماشین در پیشبینی وضعیت لختهشدن خون بند ناف پیش از تولد نوزاد، میتواند به این فرآیند کمک کند و امکان مداخله بهموقع و پیشگیری از عوارض آن را فراهــم
نماید.
در همین راستا ابتدا دادههایی که در بانک خون بند ناف رویان جمعآوری شده بود، پیشپردازش شدند و با توجه به این که دادهها بالانس نبودند، با کمک روش SMOTE بالانس شدند و سپس بهترین ویژگیها با کمک طبقهبندی درختان مازاد انتخاب شدند تا برای الگوریتمهای یادگیری ماشین آماده شوند. نتایج این روش نشان دادند که جنسیت نوزاد بیشترین اهمیت را در بروز لخته در خون بند ناف پس از زایمان دارد که حیفض نیز در پژوهش خود به آن اشاره کرده است (5). همچنین با توجه به ادبیات موضوع دیابت، فشار خون نقش مستقیمی در لخته شدن خون بند ناف نوزاد دارد که این پژوهش با انتخاب آن به عنوان بهترین ویژگیها این موضوع را تصدیق میکند (7، 4).
همچنین فاکتورهای تاثیرگذار جدید توسط مدل درخت مازاد شناسایی شدند که پیش از این در ادبیات موضوع شناسایی نشده بودند. مکان تولد نوزاد، نوع زایمان، هفته بارداری و ازدواج فامیلی، به ترتیب با 11/0، 1/0، 1/0 و 86/0 وزن از دیگر عوامل مهم در پیشبینی لختهشدن خون بند ناف هستند.
مدل با استفاده و مقایسه الگوریتمهای طبقهبندی یادگیری با نظارت درخت تصمیم، بیزین ساده، k-نزدیکترین همسایه، ماشینبردار پشتیبان، جنگل تصادفی، رأیگیری اکثریت و پرسپترون چندلایه اجرا شد.
نتیجهگیری
عملکرد بالای دو روش جنگل تصادفی و k-نزدیکترین همسایه با دقتهای به ترتیب (84/0) و (83/0) نشان میدهد که میتوان با کمک الگوریتمهای یادگیری ماشین با دقت بالایی لختهشدن خون بند ناف نوزاد را پیش از زایمان پیشبینی کرد و به کمک آن از نمونهبرداری نمونههای دارای لخته بهمنظور کاهش هزینه و مشکلات ذخیرهسازی آنها جلوگیری کرد. عملکرد نسبتاًً متوسط الگوریتم پرسپترون چندلایه در مقایسه با روشهای اشاره شده نشان میدهد که در جایی که روشهای
کلاسیک یادگیری ماشین عملکرد بالایی از خود نشان میدهند، نیازی به استفاده از روشهای شبکههای عصبی عمیق نیست. همچنین عملکرد نسبتاً پایین دو روش بیزین ساده و ماشینبردار پشتیبان با دقتهای به ترتیب 63/0 و 65/0، نقش انتخاب روش مناسب برای پیشبینی لختهشدن و اهمیت مقایسه روشهای مختلف را نشان میدهد.
پیشنهاد میشود در پژوهشهای آتی، از روشهای دیگری برای انتخاب ویژگی استفاده شود. همچنین سابقه بیماریهای بیشتری برای تکمیل دادهها در نظر گرفته شود. روشهای پیچیدهتر تنظیم هایپرپارامترها نیز بررسی شده تا نتایج با دقت پیشبینی بالاتری ارائه شوند.
حمایت مالی
مطالعه فوق بدون حمایت مالی ارگان و نهاد خاصی انجام شده است.
ملاحظات اخلاقی
این پروژه از کمیته اخلاق در پژوهش دانشگاه خوارزمی با کد اخلاق IR.KHU.REC.1402.068 در تاریخ 2/8/1402 مجوز گرفته است.
عدم تعارض منافع
نویسندگان اظهار کردند در انتشار این اثر منافع تجاری نداشتند و در مقابل ارائه اثر وجهی دریافت نکردهاند.
نقش نویسندگان
امیر حسین اسماعیلپور: تحلیل و بررسی دادهها، اجرای روشها، نوشتن مقاله
دکتر مریم عاملی: نظارت بر اجرای روشها، روششناسی و تفسیر نتایج، ویرایش مقاله
دکتر اشکان مزدگیر: طراحی مطالعه، روششناسی، ویرایش مقاله
دکتر اُرد احمدی: بررسی روشها و نتایج
دکتر مرتضی ضرابی: فراهم آوردن دادههای مورد نیاز، طراحی مطالعه
متن کامل: (1037 مشاهده)
پیشبینی لخته شدن خون بند ناف پیش از جمعآوری با کمک الگوریتمهای
یادگیری ماشین پیشرفته
امیرحسین اسمعیلپور1، مریم عاملی2، اشکان مزدگیر3، اُرد احمدی3، مرتضی ضرابی4
چکیده
سابقه و هدف
خون بند ناف منبع ارزشمندی از سلولهای بنیادی است که در پیوند برای درمان بیماریهای مختلف از جمله لوسمی، لنفوم و اختلالات ژنتیکی مورد استفاده قرار میگیرد. با این حال، لخته شدن خون بند ناف در فرآیند جمعآوری میتواند کیفیت نمونه را کاهش دهد و بر اثر بخشی آن در ذخیرهسازی خون بند ناف در بانکها تأثیر بگذارد. در این مقاله با استفاده از روشهای پیشرفته یادگیری ماشین، لختهشدن خون بند ناف قبل از جمعآوری نمونهها از اهداکنندگان پیشبینی شده است.
مواد و روشها
در یک مطالعه گذشتهنگر، تعداد 928127 نمونه از بانک خون بند ناف رویان از سال 1384 تا 1400 بررسی شدند. دادهها با استفاده از نمونههای موجود در بانک خون بند ناف رویان و با استفاده از الگوریتمهای طبقهبندی یادگیری نظارت شده، از جمله درخت تصمیم، بیزین ساده، K- نزدیکترین همسایه، ماشینبردار پشتیبان، جنگل تصادفی، طبقهبندی رأی اکثریت و پرسپترون چند لایه برای پیشبینی لختهشدن خون بند ناف بر روی دادههای بانک خون بند ناف رویان اجرا و عملکرد آنها با استفاده از معیارهای ارزیابی دقت، صحت، بازخوانی و امتیاز F1 مقایسه شد.
یافتهها
در این مطالعه دقت الگوریتم درخت تصمیم 80/0، بیزین ساده 63/0، K- نزدیکترین همسایه 83/0، ماشینبردار پشتیبان 65/0، جنگل تصادفی 84/0، طبقهبندی رأی اکثریت 81/0 و پرسپترون چند لایه 74/0 اندازهگیری شده است.
نتیجه گیری
در این مطالعه عملکرد دو الگوریتم جنگل تصادفی و K- نزدیکترین همسایه بهترین کارآیی را از خود نشان دادند و بیانگر آن است که میتوان با کمک الگوریتمهای یادگیری ماشین، با دقت بالایی بروز لخته پیش از زایمان را در نوزاد پیشبینی کرد و به کمک آن میتوان از نمونهبرداری نمونههای دارای لخته به منظور کاهش هزینه و مشکلات ذخیرهسازی آنها جلوگیری نمود.
کلمات کلیدی: سلولهای بنیادی، یادگیری ماشین، خون بند ناف، بیوانفورماتیک
تاریخ دریافت: 18/10/1402
تاریخ پذیرش: 21/03/1403
1- دانشجوی دکترای مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی ـ تهران ـ ایران
2- مؤلف مسئول: دکترای مهندسی صنایع ـ استادیار گروه مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی ـ تهران ـ ایران ـ کدپستی: 1571914911
3- دکترای مهندسی صنایع ـ استادیار گروه مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی ـ تهران ـ ایران
4- پزشک عمومی ـ گروه پزشکی بازساختی ـ پژوهشکده زیست شناسی و فناوری سلولهای بنیادی ـ پژوهشگاه رویان ـ تهران ـ ایران
یادگیری ماشین پیشرفته
امیرحسین اسمعیلپور1، مریم عاملی2، اشکان مزدگیر3، اُرد احمدی3، مرتضی ضرابی4
چکیده
سابقه و هدف
خون بند ناف منبع ارزشمندی از سلولهای بنیادی است که در پیوند برای درمان بیماریهای مختلف از جمله لوسمی، لنفوم و اختلالات ژنتیکی مورد استفاده قرار میگیرد. با این حال، لخته شدن خون بند ناف در فرآیند جمعآوری میتواند کیفیت نمونه را کاهش دهد و بر اثر بخشی آن در ذخیرهسازی خون بند ناف در بانکها تأثیر بگذارد. در این مقاله با استفاده از روشهای پیشرفته یادگیری ماشین، لختهشدن خون بند ناف قبل از جمعآوری نمونهها از اهداکنندگان پیشبینی شده است.
مواد و روشها
در یک مطالعه گذشتهنگر، تعداد 928127 نمونه از بانک خون بند ناف رویان از سال 1384 تا 1400 بررسی شدند. دادهها با استفاده از نمونههای موجود در بانک خون بند ناف رویان و با استفاده از الگوریتمهای طبقهبندی یادگیری نظارت شده، از جمله درخت تصمیم، بیزین ساده، K- نزدیکترین همسایه، ماشینبردار پشتیبان، جنگل تصادفی، طبقهبندی رأی اکثریت و پرسپترون چند لایه برای پیشبینی لختهشدن خون بند ناف بر روی دادههای بانک خون بند ناف رویان اجرا و عملکرد آنها با استفاده از معیارهای ارزیابی دقت، صحت، بازخوانی و امتیاز F1 مقایسه شد.
یافتهها
در این مطالعه دقت الگوریتم درخت تصمیم 80/0، بیزین ساده 63/0، K- نزدیکترین همسایه 83/0، ماشینبردار پشتیبان 65/0، جنگل تصادفی 84/0، طبقهبندی رأی اکثریت 81/0 و پرسپترون چند لایه 74/0 اندازهگیری شده است.
نتیجه گیری
در این مطالعه عملکرد دو الگوریتم جنگل تصادفی و K- نزدیکترین همسایه بهترین کارآیی را از خود نشان دادند و بیانگر آن است که میتوان با کمک الگوریتمهای یادگیری ماشین، با دقت بالایی بروز لخته پیش از زایمان را در نوزاد پیشبینی کرد و به کمک آن میتوان از نمونهبرداری نمونههای دارای لخته به منظور کاهش هزینه و مشکلات ذخیرهسازی آنها جلوگیری نمود.
کلمات کلیدی: سلولهای بنیادی، یادگیری ماشین، خون بند ناف، بیوانفورماتیک
تاریخ دریافت: 18/10/1402
تاریخ پذیرش: 21/03/1403
1- دانشجوی دکترای مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی ـ تهران ـ ایران
2- مؤلف مسئول: دکترای مهندسی صنایع ـ استادیار گروه مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی ـ تهران ـ ایران ـ کدپستی: 1571914911
3- دکترای مهندسی صنایع ـ استادیار گروه مهندسی صنایع ـ دانشکده فنی و مهندسی دانشگاه خوارزمی ـ تهران ـ ایران
4- پزشک عمومی ـ گروه پزشکی بازساختی ـ پژوهشکده زیست شناسی و فناوری سلولهای بنیادی ـ پژوهشگاه رویان ـ تهران ـ ایران
مقدمه
خون بند ناف (Umbilical Cord Blood: UCB) منبع غنی از سلولهای بنیادی خونساز است که میتواند در درمان اختلالات ژنتیکی، نقص ایمنی و اختلالات خونی مورد استفاده قرار گیرد. پیوند خون بند ناف یک روش پزشکی است که در آن سلولهای بنیادی خون بند ناف یک نوزاد سالم به بیمار پیوند زده میشود. این پیوند برای درمان بیماریهای مختلفی از جمله سرطانهای خون، اختلالات خونی، سندرمهای نارسایی مغز استخوان و اختلالات ایمنی کاربرد دارد (1).
یکی از چالشهای اصلی در جمعآوری خون بند ناف، بروز لختههای خون در بند ناف است که مانع از جریان خون و کاهش تولید سلولهای بنیادی میشود. بدین ترتیب جمعآوری و ذخیرهسازی UCB با وجود لخته در بند ناف میتواند پیچیده شده و عملکرد سلولهای بنیادی را کاهش داده و کیفیت آنها را به خطر بیندازد؛ بنابراین، پیشبینی احتمال لختهشدن بند ناف قبل از جمعآوری میتواند به اطمینان از عملکرد بالاتر سلولهای بنیادی و نتایج بهتر برای بیماران کمک کند و به پزشکان در تصمیمگیری آگاهانه کمک نماید (2).
بند ناف از دو شریان و یک ورید تشکیل شده است که اکسیژن و مواد مغذی را به جنین میرساند و مواد زائد را دفع میکند. بند ناف همچنین حاوی ماده ژلاتینی به نام ژله وارتون است که از فشرده شدن رگها جلوگیری میکند. با این حال، در حین زایمان، بند ناف میتواند فشرده یا پیچ خورده شود و منجر به تشکیل لخته گردد. عوامل متعدد دیگری نیز ممکن است در شکلگیری لخته در خون بند ناف نقشآفرین باشند (3). برخی از این عوامل که ریشه در بیماریهای مادر و نوزاد دارند، مانند دیابت مادر در زمان بارداری، رابطه مستقیم با لختهشدن خون نوزاد دارند (4). حیفض و همکاران در پژوهش خود 52 مورد لخته شدن بند ناف از 3 جمعیت مختلف را مورد تجزیه وتحلیل قرار داده و با 68 مورد از ادبیات موضوع مقایسه کرد که بدین ترتیب مجموعهای از عوامل و بیماریهای مختلف را در شکلگیری لخته مورد بررسی قرار داد و به این نتیجه رسیـد کـه در نوزادان پسر احتمال بیشتری برای
لختهشـدن وجـود دارد (5). در این پژوهش عواملی همچون عوارض مامایی مانند انواع عفونت و شرایط سیستمیک جنین مانند دیابت و خونریزی جنینی مهم ارزیابی شدند. از جمله عامل دیگری که در ایجاد لخته تاثیرگذار است، کمخونی مادر میباشد (6). تغییرات انعقاد خون بند ناف در فشار خون مادر در پژوهش لاکس مورد بررسی قرار گرفت (7). این پژوهش همچنین به این نتیجه رسید که آسیب کبدی به عنوان یکی از اصلیترین علل انعقاد خون بند ناف نوزاد مطرح است.
با توجه به این که پیشبینی لخته شدن خون بند ناف پیش از زایمان میتواند منجر به بهبود کمیت و کیفیت شود و به علاوه صرفه جویی اقتصادی به همراه داشته باشد، لذا استفاده از مدلهای پیشبینی کننده در این زمینه، امری ضروری است. امروزه روشهای یادگیری ماشین (Machine Learning: ML) به عنوان ابزاری قدرتمند برای پیشبینی پدیدهها و متغیرهای مختلف در علوم گوناگون به کار میروند. هر چند هنوز مطالعهای به منظور پیشبینی لختهشدن خون بند ناف با این ابزار صورت نگرفته است. از این رو در ادامه پژوهشهایی که از ML برای کنترل کیفیت سلولهای بنیادی استفاده کردهاند، مورد بررسی قرار میگیرند.
هدف بسیاری از پژوهشها در این حوزه تعریف پیشبینیکنندههای بالینی قبل از تولد برای تعداد سلولهای هستهدار (Total Nucleated Cell count: TNC) است که به شناسایی اهداکنندگان موفق واحدهای خون بند ناف قبل از شروع زایمان فعال کمک میکند. این پژوهشها با پیشبینی TNC تلاش میکنند تا کارآیی بانک خون در ذخیرهسازی نمونههای بهتر را افزایش دهند. این مطالعهها از روشهای یادگیری گروهی (Ensemble Learning) و روشهای کلاسیک ML مانند درخت تصمیم استفاده کردند (9، 8). همچنین هاره با کمک رگرسیون به این نتیجه رسید که سن حاملگی، نژاد مادر و وزن و جنس نوزاد با TNC ارتباط دارد (11، 10). با کمک یادگیری ماشین و روشهای آماری مختلف مانند شبکههای عصبی پرسپترون چند لایه، رگرسیون لجستیک و درخت تصمیم، ارزش کیفـی نمونههـای خـون و دستهبنـدی مناسب آنها
(برای دور انداختن یا انجماد) را تعیین کرد.
همان طور که پژوهشهای بالا نشان میدهند، روشهای یادگیری ماشین توانایی لازم برای ارائه پیشبینی کیفیت خون بند ناف را دارا هستند اما این روشها برای پیشبینی وجود و یا بروز لخته در خون بند ناف پیش از زایمان استفاده نشدهاند. هدف این مقاله، پیشبینی لختهشدن خون بند ناف پیش از جمعآوری نمونهها از اهداکنندگان با کمک روشهای یادگیری ماشین پیشرفته بود. عملکرد الگوریتمهای مختلف یادگیری ماشینی برای پیشبینی لختهشدن خون بند ناف ارزیابی شده و در مورد پیامدهای بالقوه این یافتهها برای عمل بالینی بحث میشود.
مواد و روشها
در این پژوهش از زبان برنامهنویسی پایتون (Python) استفاده شده است که یک زبان برنامهنویسی سطح بالا و همه منظوره است. پایتون یک زبان قدرتمند با طیف گستردهای از کتابخانهها و ابزارها محسوب میشود. تا سال 2020، 89% پژوهشهای مربوط به ML با کمک زبان پایتون نوشته شده است (12).
توصیف مجموعه دادهها:
این پژوهش از نوع گذشتهنگر بود. دادهها شامل
928127 نمونه جمعآوری شده در بانک خون بند ناف رویان از سال 1384 تا 1400 بود. این دادهها ۸۶ ستون (ویژگی) شامل اطلاعات مربوط به لخته شدن و برخی از ویژگیهای هر اهداکننده هستند. معیار انتخاب این ویژگیها در دسترسبودن و قابلیت اندازهگیری آنها پیش از تولد نوزاد بود. ویژگیهایی که تعداد رکوردهای آنها به طور قابلتوجهی از دست رفته بود نیز حذف شدند. در نهایت تعداد ستونهای مورد بررسی (بدون ستون هدف یعنی لخته بودن خون بند ناف) ۳۲ ویژگی را تشکیل دادند. لازم به ذکر است که ویژگیهای مربوط به سابقه بیماری در خانواده، پیش از این و توسط مجموعه بانک خون رویان به کمک پرسشنامهای آنلاین جمعآوری شده است. برای دادهها و رکوردهایی که ازدست رفته و یا پرت بودند، سطر مربوط به آنها از بین مجموع سطرها حذف شد. در یادگیری ماشین، الگوریتمها بر اساس ویژگیهایی که از دادهها استخراج میشوند، یاد میگیرند. این ویژگیها در واقع پیشبینی کنندههای لختگی خون بند ناف هستند یعنی نشانههایی هستند که به الگوریتم کمک میکنند تا الگوهایی را در دادهها شناسایی کند و از آنها برای پیشبینی یا تصمیمگیری استفاده کند (13). در شکل گامهای پژوهش به منظور پیشبینی بروز لخته به صورت شماتیک رسم شدهاند (شکل 1).
ستون هدف برای پیشبینی لخته بودن خون بند ناف پیش از اهدا شامل دو دسته به صورت باینری است. دسته اول شامل نمونههایی است که دارای لخته هستند و دسته دوم شامل نمونههایی است که لخته ندارند.
با توجه با این که دسته اول شامل 25089 نمونه و دسته دوم شامل 100765 نمونه بود، مشخص میشود دادهها نامتوازن هستند. در الگوریتمهای طبقهبندی استاندارد، توزیع کلاسها متوازن در نظر گرفته میشود و این دسته از الگوریتمها در مواجهه با مجموعهدادههای نامتوازن، عملکرد مناسبی را از خود ارائه نمیدهند؛ چرا که الگوریتمهای معمول طبقهبندی به سمت نمونههای آموزشی کلاس بزرگتر متمایل میشوند که این موضوع باعث افزایش خطا در شناسایی نمونههای اقلیت میشود (14). به منظور مقابله با این مشکل، در این پژوهش از روش نمونهبرداری بیش از حد اقلیت مصنوعی (Synthetic Minority Oversampling Technique: SMOTE) استفاده شد که امکان تولید دادههای مصنوعی را فراهم میسازد. این روش با استفاده از همسایههای هر نمونه از کلاس اقلیت، نمونههای مصنوعی جدیدی میسازد. به این صورت که در مرحله اول، بهازای هر نمونه
جدید در نظر گرفته میشوند.
برای انتخاب بهترین ویژگیها برای استفاده در الگوریتمهای یادگیری ماشین و بهبود کیفیت آنها از روش طبقهبندی درختان مازاد (Extra Tree) استفاده شد. الگوریتم درختان مازاد، مانند الگوریتم جنگلهای تصادفی، درختهای تصمیمگیری زیادی ایجاد میکند، اما نمونهگیری برای هر درخت، تصادفی و بدون جایگزینی است (15).
روشهای یادگیری ماشین:
برای اجرای مدل اصلی با به کارگیری تعدادی از الگوریتمهای یادگیری ماشین با ناظر و اجرای آن بر روی دادههایی که در بخش قبلی بررسی شدند، بروز لخته در خون بند ناف نوزاد پیش از تولد پیشبینی شد.
به منظور ارزیابی دقت و کارآیی الگوریتمها در پیشبینی، از جمله شاخصهایی که مورد بررسی قرار گرفتهاند شامل دقت (Accuracy) صحت (Precision)، بازخوانی (Recall) و امتیاز
برای تنظیم فراپارامتر (Hyperparameter) در الگوریتمهای یادگیری ماشینی از روش جستجوی شبکهای (Grid Search) استفاده شد که شامل جستجو در محدودهای از مقادیر فراپارامتر برای یافتن ترکیب بهینه فراپارامترها است که بهترین عملکرد را در یک مجموعه داده معین ایجاد میکند (16). فراپارامترهای کلیدی و اندازههای آزمایش بر اساس تأثیر قابل توجه آنها بر عملکرد و کارآیی محاسباتی مدل انتخاب شدند، که امکان ایجاد فضای جستجوی قابل مدیریت را فراهم میآورد و در عین حال نتایج بهینهسازی قوی را تضمین میکند. همچنین لازم به ذکر است که پس از فراخوانی دادهها و اجرای روش SMOTE ، آنها به دو دسته دادههای تمرینی (80%) و دادههای تست (20%) تقسیم شدند.
الگوریتمهای مورداستفاده در این پژوهش شامل الگوریتمهای زیر است:
- درخت تصمیم(Decision Tree): درخت تصمیم اغلب برای مسائل دستهبندی استفاده میشود و به خوبی میتواند دادههای پیچیده را تفکیک کند.
- دستهبندی بیز ساده(Naïve Baysian): این مدل بر اساس تئوری احتمال بیز عمل میکند و برای دادههای مستقل از هم مناسب است.
- k-نزدیکترین همسایگی(K-nearest Neighbors): این الگوریتم بر اساس فاصله نزدیکترین همسایهها کار میکند و برای مسائل تشخیص الگو مناسب است.
- ماشین بردار پشتیبان(Support Vector Machines): ماشینبردار پشتیبان برای مسائل دستهبندی خطی و غیرخطی کاربرد دارد.
- جنگل تصادفی(Random Forest):جنگل تصادفی از ترکیب چندین درخت تصمیم برای بهبود دقت و کاهش بیشبرازش استفاده میکند.
- طبقهبندی رأیگیری اکثریت (Majority-Voting Classifier): این مدل از ترکیب چند مدل مختلف برای بهبود دقت نهایی استفاده میکند.
- پرسپترون چندلایه (Multilayer Perceptron): این مدل یکی از انواع شبکههای عصبی است که برای مسائل پیچیده و غیرخطی مناسب است (18، 17).
یافتهها
پس از متوازنسازی دادهها با روش SMOTE مجموعه دادهها برای انتخاب بهترین ویژگیها آماده شدند. پس از اجرای الگوریتم درختان مازاد میتوان دید که ویژگی "جنسیت نوزاد" با مقدار وزن 12/0 بیشترین تأثیر را در مدل دارد. پس از آن، ویژگیهای "مکان تولد" و "نوع زایمان" به ترتیب با وزنهای 11/0 و 10/0 قرار دارند. ویژگیهای دیگری مانند "هفته بارداری" و "ازدواج فامیلی" نیز تأثیر قابل توجهی دارند. در مقابل، ویژگیهایی مانند "سابقه اهدا خون" و "سابقه هپاتیت C " کمترین اهمیت را در مدل دارند( شکل 2). شکل 2 نمایی از اهمیت تمام ویژگیها را نشان میدهد که محور افقی میزان اهمیت هر ویژگی و محور عمودی نام ویژگیها را نشان میدهد. ویژگیها بر اساس اهمیت و وزن داده شده توسط الگوریتم به صورت نزولی مرتب شدهاند. بر این اساس ۱۸ ویژگی با بیشترین اهمیت (جنسیت نوزاد تا سابقه فشارخون) برای اجرای الگوریتمهای بعدی انتخاب میشوند.
نتایج نشان میدهد که جنگل تصادفی بهترین دقت (84/0)، بالاترین صحت (95/0) و امتیاز F1 (84/0) را به اجرا گذاشته است اما بازخوانی متوسط (73/0) میتواند نشاندهنده این باشد که این مدل در شناسایی همه موارد مثبت موثر نیست. مدل k-نزدیکترین همسایه با دقت (83/0)، صحت (80/0)، بازخوانی (89/0) و امتیاز F1 (84/0) کارآیی بالایی در همه شاخصها را از خود نشان داده است و بیانگر آن است که برای پیشبینی لختهشدن خون بند ناف مناسب اسـت. رأیگیـری اکثریت و درخت تصمیم عملکرد نسبتاً خوبی را در همه شاخصها از خود نشان داده است و مشخص میکند که میتوان از آنها نیــز
به عنوان الگوریتمهای قابل اطمینان برای پیشبینی لخته استفاده کرد. پرسپترون چندلایه نتایج نسبتاً متوسطی را در مقایسه با دیگر روشها نتیجه داده است. دستهبندی بیز ساده با وجود بازخوانی نسبتا خوب (79/0) عملکرد ضعیفی در دیگر شاخصها دارد. ماشین بردار پشتیبان اما عملکرد ضعیفی نسبت به سایر مدلها دارد که میتوان گفت استفاده از این روش برای پیشبینی لخته مناسب نیست. بعد از اجرای هر الگوریتم و عیبیابی، کارآیی الگوریتمها با هم مقایسه شدند (جدول 1).
بحث
در این مطالعه مدل یادگیری ماشینی برای پیشبینی لختهشدن خون بند ناف پیش از تولد نوزاد با استفاده از دادههای بالینی و آزمایشگاهی طبقهبندی شد. شناسایی بند نافهایی که در معرض خطر بروز لختهشدن هستند، تأثیر به سزایی در کیفیت خون جمعآوری شده به منظور ذخیرهسازی در بانکهای بند ناف و همچنین کاهش هزینه جمعآوری و آزمایش در این بانکها دارد. استفاده از یادگیری ماشین در پیشبینی وضعیت لختهشدن خون بند ناف پیش از تولد نوزاد، میتواند به این فرآیند کمک کند و امکان مداخله بهموقع و پیشگیری از عوارض آن را فراهــم
نماید.
در همین راستا ابتدا دادههایی که در بانک خون بند ناف رویان جمعآوری شده بود، پیشپردازش شدند و با توجه به این که دادهها بالانس نبودند، با کمک روش SMOTE بالانس شدند و سپس بهترین ویژگیها با کمک طبقهبندی درختان مازاد انتخاب شدند تا برای الگوریتمهای یادگیری ماشین آماده شوند. نتایج این روش نشان دادند که جنسیت نوزاد بیشترین اهمیت را در بروز لخته در خون بند ناف پس از زایمان دارد که حیفض نیز در پژوهش خود به آن اشاره کرده است (5). همچنین با توجه به ادبیات موضوع دیابت، فشار خون نقش مستقیمی در لخته شدن خون بند ناف نوزاد دارد که این پژوهش با انتخاب آن به عنوان بهترین ویژگیها این موضوع را تصدیق میکند (7، 4).
همچنین فاکتورهای تاثیرگذار جدید توسط مدل درخت مازاد شناسایی شدند که پیش از این در ادبیات موضوع شناسایی نشده بودند. مکان تولد نوزاد، نوع زایمان، هفته بارداری و ازدواج فامیلی، به ترتیب با 11/0، 1/0، 1/0 و 86/0 وزن از دیگر عوامل مهم در پیشبینی لختهشدن خون بند ناف هستند.
مدل با استفاده و مقایسه الگوریتمهای طبقهبندی یادگیری با نظارت درخت تصمیم، بیزین ساده، k-نزدیکترین همسایه، ماشینبردار پشتیبان، جنگل تصادفی، رأیگیری اکثریت و پرسپترون چندلایه اجرا شد.
نتیجهگیری
عملکرد بالای دو روش جنگل تصادفی و k-نزدیکترین همسایه با دقتهای به ترتیب (84/0) و (83/0) نشان میدهد که میتوان با کمک الگوریتمهای یادگیری ماشین با دقت بالایی لختهشدن خون بند ناف نوزاد را پیش از زایمان پیشبینی کرد و به کمک آن از نمونهبرداری نمونههای دارای لخته بهمنظور کاهش هزینه و مشکلات ذخیرهسازی آنها جلوگیری کرد. عملکرد نسبتاًً متوسط الگوریتم پرسپترون چندلایه در مقایسه با روشهای اشاره شده نشان میدهد که در جایی که روشهای
کلاسیک یادگیری ماشین عملکرد بالایی از خود نشان میدهند، نیازی به استفاده از روشهای شبکههای عصبی عمیق نیست. همچنین عملکرد نسبتاً پایین دو روش بیزین ساده و ماشینبردار پشتیبان با دقتهای به ترتیب 63/0 و 65/0، نقش انتخاب روش مناسب برای پیشبینی لختهشدن و اهمیت مقایسه روشهای مختلف را نشان میدهد.
پیشنهاد میشود در پژوهشهای آتی، از روشهای دیگری برای انتخاب ویژگی استفاده شود. همچنین سابقه بیماریهای بیشتری برای تکمیل دادهها در نظر گرفته شود. روشهای پیچیدهتر تنظیم هایپرپارامترها نیز بررسی شده تا نتایج با دقت پیشبینی بالاتری ارائه شوند.
حمایت مالی
مطالعه فوق بدون حمایت مالی ارگان و نهاد خاصی انجام شده است.
ملاحظات اخلاقی
این پروژه از کمیته اخلاق در پژوهش دانشگاه خوارزمی با کد اخلاق IR.KHU.REC.1402.068 در تاریخ 2/8/1402 مجوز گرفته است.
عدم تعارض منافع
نویسندگان اظهار کردند در انتشار این اثر منافع تجاری نداشتند و در مقابل ارائه اثر وجهی دریافت نکردهاند.
نقش نویسندگان
امیر حسین اسماعیلپور: تحلیل و بررسی دادهها، اجرای روشها، نوشتن مقاله
دکتر مریم عاملی: نظارت بر اجرای روشها، روششناسی و تفسیر نتایج، ویرایش مقاله
دکتر اشکان مزدگیر: طراحی مطالعه، روششناسی، ویرایش مقاله
دکتر اُرد احمدی: بررسی روشها و نتایج
دکتر مرتضی ضرابی: فراهم آوردن دادههای مورد نیاز، طراحی مطالعه
نوع مطالعه: پژوهشي |
موضوع مقاله:
سلولهاي بنيادي
ارسال پیام به نویسنده مسئول
| بازنشر اطلاعات | |
 |
این مقاله تحت شرایط Creative Commons Attribution-NonCommercial 4.0 International License قابل بازنشر است. |
